From Pilot to Production: Why Most AI Projects Get Stuck (And How to Move Them)
I've been building systems that have to survive contact with reality for over thirty years. I founded adoption.com in 1995 while working at Cap Gemini, helping businesses develop internet strategy before Google existed. I've seen more than a few technology waves roll in promising everything and deliver something considerably more complicated. I've run operations in seven countries. I've managed teams in Ethiopia, Haiti, Kenya, and places where there was no margin for a system that only worked in ideal conditions.
I'm new to AI consulting as a client-facing practice, and I won't pretend otherwise. But when I look at the pilot-to-production problem, I recognize exactly what I'm looking at. It's not a technology problem. The model works. The demo was impressive. The data scientists are smart. And somehow the whole thing is just stuck.
There's a name for this state. It's called Pilot Purgatory, and right now, the majority of enterprises are living in it.

The Numbers Are Stark
Here's what the data actually shows. MIT's Project NANDA reviewed enterprise AI deployments and found that 95% of organizations see no measurable return to the income statement from their generative AI pilots.[1] Not a small return. Zero measurable return.
RAND Corporation puts the broader AI project failure rate at more than 80%, which is roughly twice the failure rate of comparable IT projects that don't involve AI.[2]
S&P Global Market Intelligence's 2025 Voice of the Enterprise survey found that 42% of companies abandoned most of their AI initiatives, up sharply from 17% just a year earlier.[3] They weren't abandoning failures. Many of them were abandoning pilots that looked like successes.
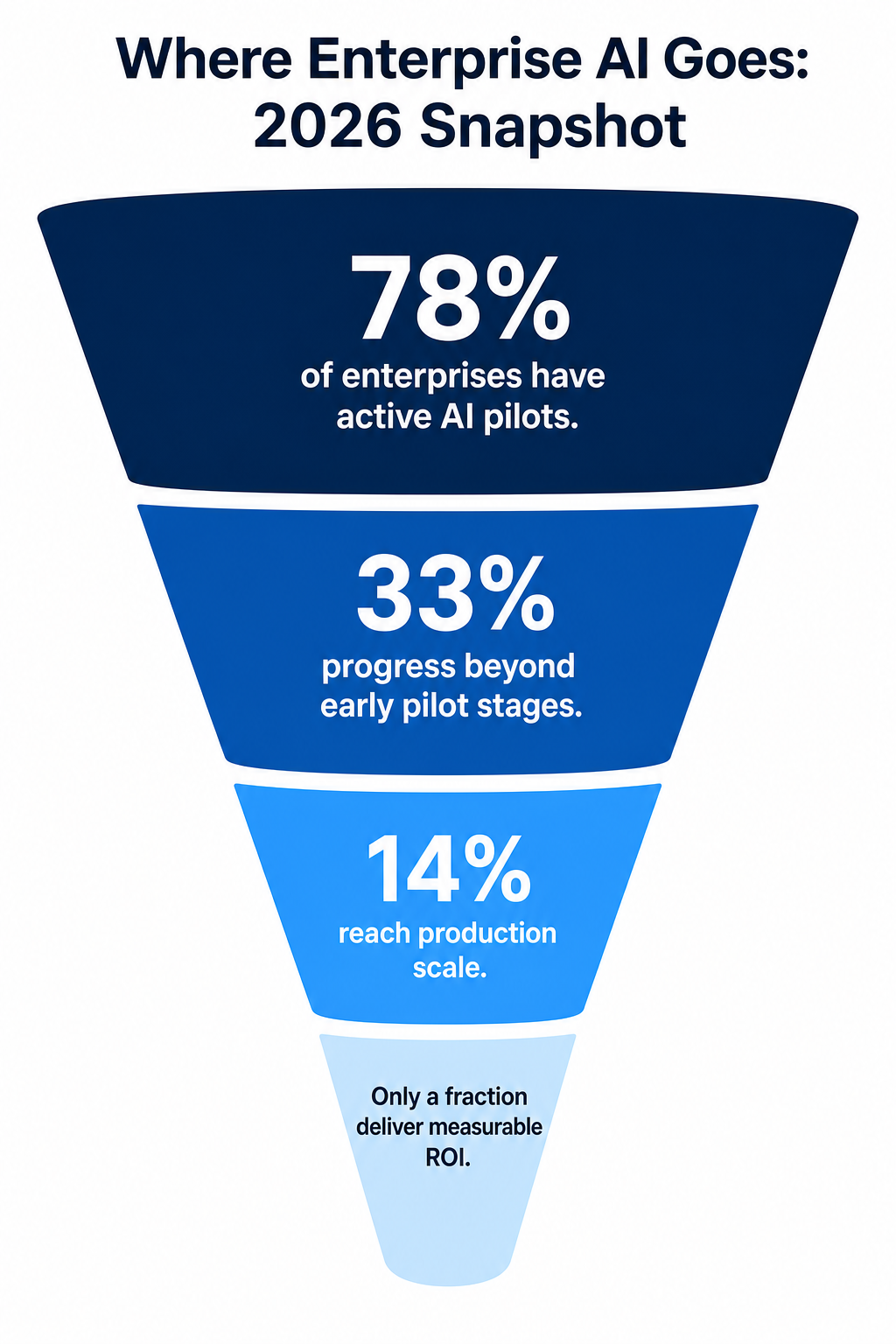
The gap between pilot and production is where the money goes. A March 2026 survey of 650 enterprise technology leaders found that 78% of enterprises have active AI agent pilots. Only 14% have reached production scale.[4]
Read that again. Seventy-eight percent started. Fourteen percent made it.
That's not a technology gap. That's an organizational gap, and it's one that specific, deliberate decisions can close.
What I Mean by Pilot Purgatory
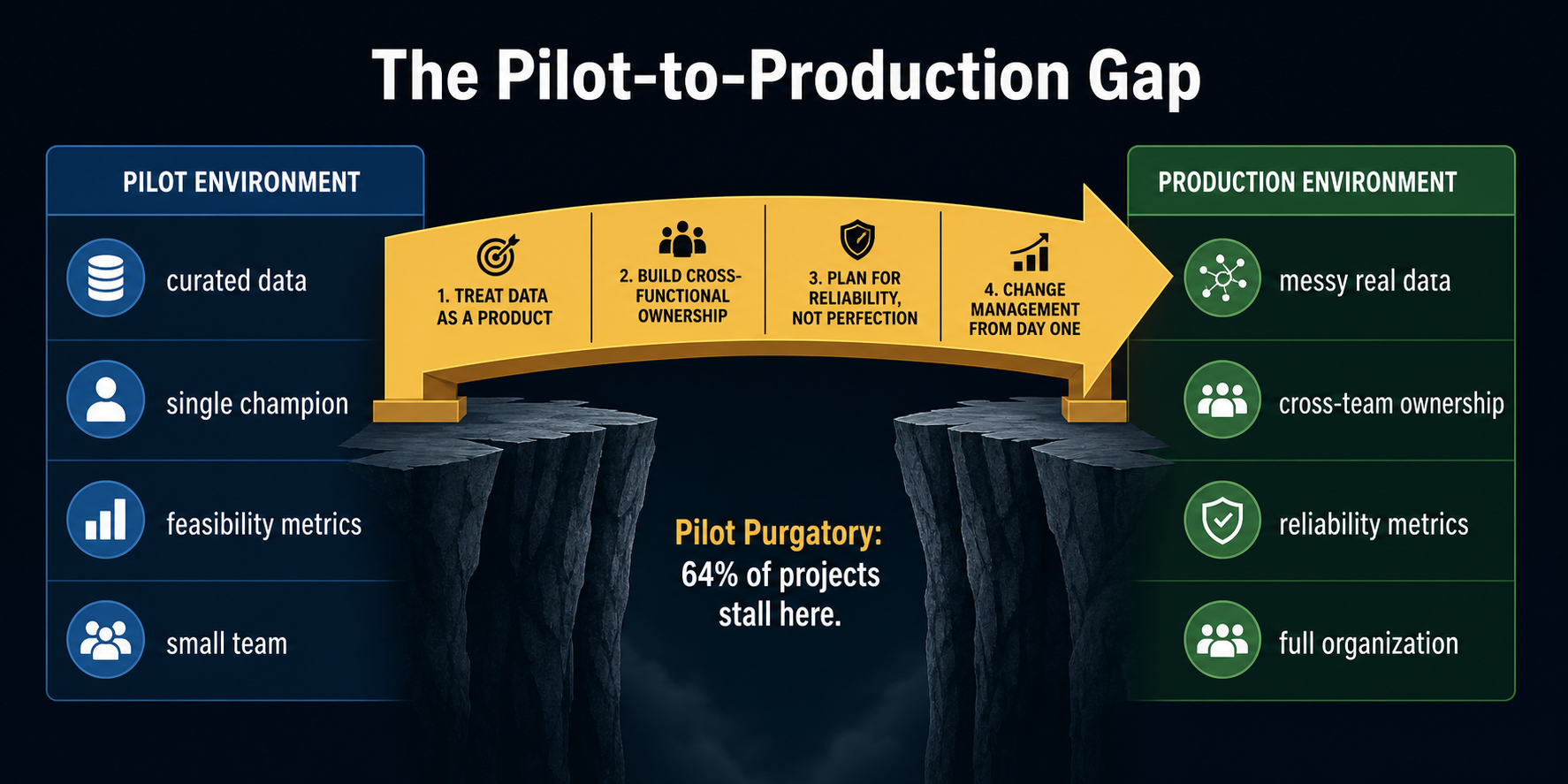
Pilot Purgatory is the state in which an organization runs multiple AI proofs of concept indefinitely, consuming resources and credibility, without any project ever graduating to production deployment.
It doesn't feel catastrophic from the inside. The pilot team is excited. The champion is enthused. The demo looks great. There are meetings about "next steps." And then the next steps don't happen, and eventually a new pilot starts somewhere else in the organization, and the cycle repeats.
The thing about Pilot Purgatory is that it's not static. It's an active drain. Every month you spend cycling through inconclusive experiments carries real cost. Gartner projects that 60% of AI projects lacking production-ready infrastructure will be abandoned through 2026.[5] That's not hypothetical. That's the trajectory.
I've watched this pattern repeat across four technology waves in my career. The internet in the mid-nineties. Enterprise software in the early 2000s. Mobile in the 2010s. And now AI. The organizations that survive each wave aren't the ones with the best pilots. They're the ones who figured out how to move from experiment to operation.
Why Pilots Succeed in Ways That Production Never Will
Before I get into what kills the transition, I want to be honest about something. Most pilots succeed precisely because they're not production. That's not a bug in the system. It's the design. And it's what makes the failure to transition so predictable.
Pilots Use Clean Data. Production Has Real Data.

This is the first and most fundamental mismatch.
Mike Leone, a principal analyst at Omdia covering data platforms and AI infrastructure, describes what he regularly witnesses: "You test on a curated dataset, maybe a few thousand clean documents, the AI looks amazing, everyone's excited. Then you point it at production. Fifteen years of SharePoint folders. Teams threads nobody's cleaned up since 2021."[6]
The output becomes erratic. Not because the AI degraded. Because it's faithfully processing the actual state of your institutional data, which turns out to be a sprawling mess of contradictory documents, duplicated records, and information organized in the way individual employees made sense of their world, not in the way a model can reason across.
In a pilot, the data team curates the inputs. In production, you get everything. The structural collapse is inevitable unless you plan for it before you scale.
Pilots Have a Champion. Production Needs a Whole Team.
Every successful pilot has a champion. Usually it's someone senior enough to clear obstacles, excited enough to push through friction, and credible enough that people listen. They pick the use case. They negotiate access to data. They keep the team motivated.
When the pilot ends and the handoff begins, that champion typically moves on to the next interesting problem. They're not bad people. That's just how organizations work. And suddenly the thing that depended on one person's energy and credibility has to run on institutional momentum, which is a very different fuel.
This is what the Digital Applied research calls the "unclear ownership" gap: the organizational structure that produced the pilot is not the structure needed for production operations. Pilots are projects. Production is ongoing operations. The transition requires a deliberate ownership transfer, not just a handoff document.[4]
Pilots Measure Feasibility. Production Measures Reliability.
In a pilot, the question is "can this work?" You're evaluating a model's performance on representative inputs. Technical metrics like accuracy, precision, and recall are exactly the right things to measure.
In production, the question is "does this work, consistently, at volume, integrated with everything else, even when the inputs are weird?" Those are completely different questions, and the metrics that answer them are also completely different.
A model achieving 94% accuracy in a pilot sounds impressive. But executive leadership evaluates investments on revenue impact, cost reduction, risk mitigation, and productivity improvement. When pilot results can't be clearly connected to those outcomes, the justification for scaling collapses.[7]
I've seen this pattern specifically in my background as a medical technologist. Clinical laboratory systems have to meet reliability standards that demo conditions simply don't test. A test that performs beautifully on known samples looks very different when it's processing 2,000 samples per shift from 47 different collection sites with varying quality controls. The failure to plan for reliability isn't the model's fault. It's a design failure in how the pilot was scoped.
The Four Things That Actually Kill the Transition
Research from multiple independent sources converges on a consistent set of failure patterns. Stratify's Enterprise AI Scaling Research 2026 found that five gaps account for 89% of scaling failures.[8] I've distilled the most damning four, because these are the ones I see companies get wrong most consistently.
1. No Real Production Data Plan
The pilot team got special access to a cleaned dataset. Maybe an engineer spent two weeks preparing it. Maybe a data analyst curated it specifically for the pilot window. Either way, it doesn't exist in production, and nobody planned for what does.
This matters because 64% of organizations cite data quality as their top challenge in AI adoption, and 77% rate their own data quality as average or worse.[9] Your pilot probably didn't surface that. It was designed not to.
What a production data plan actually requires: a data audit of every source the production system will touch, not just the clean ones; a data governance policy that handles updates, conflicts, and deletions; a remediation plan for data quality issues (and a realistic timeline, because cleaning enterprise data takes months, not weeks); and an ongoing monitoring process that catches data drift before it degrades model performance.
If your AI initiative doesn't have this documented before you attempt the scale-up, you're going to discover the data problem live, in production, when it's much more expensive to fix.
2. No Ownership Assigned for Post-Pilot
This is the failure mode I've seen most clearly in my work running operations across multiple countries. When nobody owns something, the thing degrades. Not because people are lazy. Because competing priorities exist, and without clear ownership, the AI system in production always loses to the urgent thing in front of whoever theoretically might be responsible.
The Digital Applied research describes what successful organizations do instead: they create a dedicated AI operations function, distinct from both IT infrastructure and the business unit, that owns production quality metrics, incident response, model version upgrades, and user feedback review.[4]
Before you scale, you need a RACI matrix with specific names assigned to: production quality monitoring, incident response, model updates and versioning, integration maintenance, user training and adoption, and success metric tracking. If any cell in that matrix is blank, you're not ready to scale.
This is operational discipline, not AI discipline. It's the same discipline you need to run any complex operational system reliably. I learned this running humanitarian operations, where the consequences of unclear ownership were sometimes measured in human welfare. The consequences in enterprise AI are measured in budget and credibility, but the principle is identical.
3. Success Metrics That Only Work in Demo Conditions
Your pilot probably measured model accuracy on a curated test set. It may have measured user satisfaction in a controlled rollout. It almost certainly didn't measure the things that will determine whether production is considered a success by leadership twelve months from now.
The measurement vacuum is one of the three root causes zbrain.ai's enterprise research identifies as driving the pilot trap: organizations evaluate pilots on technical indicators, but production funding decisions are made on business outcomes.[7]
Here's what actually needs to happen before you scale. Map your pilot metrics to business outcomes explicitly: if the model achieves 94% accuracy, what does that mean for the specific process it's automating? What's the dollar value of the hours saved, the errors prevented, the throughput increased? Can you verify that number against actual operational data, not projections?
Then set production success criteria before launch. Not "the model performs well" but "customer service resolution time decreases by 20% within 90 days" or "claims processing backlog drops below 500 cases per week." Something a CFO can verify independently.
If you can't state your production success metric in business terms before you launch, you've built a measuring system designed to fail. When leadership asks whether the production deployment worked, the answer will be "the model accuracy held" and that's not an answer anyone who controls the budget needs.
4. No Change Management Bridge from Pilot Team to Full Team
The people who participated in the pilot know how it works, what to expect from it, and how to interpret its outputs. They've developed intuition about its limits. They know when to override it and when to trust it.
The people who will use it in production know none of those things.
Organizations scaling AI often underestimate this gap because they're thinking about technology adoption, not behavioral change. The enterprise architecture research is clear on this: the organizational structure required for production is fundamentally different from the one that built the pilot, and the gap cannot be solved through training alone.[10]
Scaling AI requires cross-functional ownership and a cultural shift that cannot be solved through hiring. The teams who weren't part of the pilot have real concerns: Will this replace my job? What happens when it's wrong? Who do I call when it breaks? If those questions don't have clear answers before rollout, resistance is not irrational. It's a rational response to an unclear situation.
The change management bridge needs to be built before launch, not after. That means involving production users in late-stage pilot validation, not just presenting outcomes to them. It means creating feedback loops that give users a genuine way to surface errors and corrections. And it means being honest about limitations, because a system presented as infallible that then fails will create resistance that takes much longer to overcome than honest expectations would have.
How to Break Out of Pilot Purgatory
I don't believe in theoretical frameworks without operational steps. Here's what the transition actually requires.
Treat the Production Readiness Checklist as a Gate, Not a Formality
Before any pilot can be approved for scale, it needs to pass a genuine production readiness review that covers: data readiness (not "is there data" but "is the production data audited, governed, and within acceptable quality thresholds"), infrastructure (can the system handle production volume with acceptable latency and uptime SLAs), ownership (are specific names on record for every operational function), success metrics (are production success criteria defined in business terms with a measurement plan), and change management (has a training and adoption plan been built for the full production user base, not just pilot participants).
This isn't bureaucracy. It's the difference between a demo and a system.
Design Pilots to Test Production Conditions, Not Just Model Performance
The smartest pilot teams I've worked with design their pilots to surface the things that will kill them in production. That means deliberately including messy data. It means running the pilot long enough to encounter data drift and edge cases. It means testing with users who weren't involved in the design, because those are the users you'll have in production.
A pilot that only works on clean data in controlled conditions has told you something about the model. It hasn't told you anything about whether you can deploy this at scale.
Assign a Production Owner Before the Pilot Ends
The worst time to figure out who owns the production system is after the pilot ends and everyone scatters. Make the ownership assignment a formal milestone before the pilot completes. Give the production owner a seat in the final pilot review. If the right person to own production can't be identified before the pilot ends, that's a signal that the organization isn't ready to scale, regardless of how good the pilot looks.
Build the Measurement Architecture in the Pilot
If you're going to measure revenue impact in production, you need baseline data on the thing you're trying to improve. That baseline needs to be captured during or before the pilot, not after you've already deployed. Retrofitting measurement architecture onto a running production system is significantly harder than building it in from the start.
Be Honest About the Timeline
Production deployment is not a handoff. It's a new project with its own timeline, its own risks, and its own resource requirements. The Harvard Business Review's finding that over 80% of AI projects fail to deliver business value at scale[2] is partly a planning failure: organizations treat the pilot as the main event and the production deployment as a detail.
Realistically, moving from a successful pilot to production-scale deployment takes three to nine months, depending on integration complexity, data readiness, and organizational change requirements. That's not a sign that something's wrong. That's what the work actually costs.
What This Looks Like From the Outside
I helped businesses navigate the internet before the modern web existed, at Cap Gemini in the 1990s. I watched organizations treat websites as experiments for three years, then scramble to catch up when it became clear they weren't experiments anymore. The same pattern is happening now with AI, and it's moving faster.
The organizations that will differentiate themselves over the next three years aren't the ones with the most pilots. They're the ones that treat production deployment as the actual goal, design pilots to prove production readiness, and build the organizational infrastructure to operate AI systems reliably.
I'm not a technologist who learned business. I'm a business operator who mastered technology, and I've been hands-on building AI agents using Claude Code and Codex, not just advising on them from the outside. That distinction matters here, because the pilot-to-production problem isn't fundamentally a technology problem. It's an operations problem. And operations problems have operational solutions: clear ownership, honest metrics, real data, and deliberate change management.
The 14% of organizations that have successfully scaled AI pilots to production aren't smarter than the 78% who are stuck.[4] They just treated the production deployment as the actual project, not as the step that happens after the real project ends.
If you're in Pilot Purgatory right now, the way out isn't a better model. It's a better plan.
Annette Thompson is the founder of Verity Agentic, an AI systems consulting firm. She founded adoption.com in 1995, spent years at Cap Gemini helping businesses navigate the internet before Google existed, and has 30 years of experience building systems that survive contact with reality.
Sources
[1] MIT Project NANDA, "Generative AI Enterprise Pilot Performance Analysis," Fortune reporting, 2025. https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/
[2] RAND Corporation, "Enterprise AI Project Failure Analysis," 2024. Reported via Pertama Partners, "AI Project Failure Statistics 2026: The Complete Picture," https://www.pertamapartners.com/insights/ai-project-failure-statistics-2026
[3] S&P Global Market Intelligence, "Voice of the Enterprise Survey 2025," reported via Fullview, "200+ AI Statistics and Trends for 2025." https://www.fullview.io/blog/ai-statistics
[4] Digital Applied, "AI Agent Scaling Gap March 2026: Pilot to Production," March 2026. https://www.digitalapplied.com/blog/ai-agent-scaling-gap-march-2026-pilot-to-production
[5] Gartner, "AI Infrastructure and Operations Leader Survey," April 2026, cited in Enterprise Architecture Professional Journal, "Why AI Pilots Fail to Scale," May 2026. https://eapj.org/why-ai-pilots-fail-to-scale/
[6] Mike Leone (Principal Analyst, Omdia), quoted in UC Today, "AI Pilot Purgatory: Why Enterprise AI Rollouts Fail to Scale and How to Fix the ROI Trap." https://www.uctoday.com/productivity-automation/ai-pilot-purgatory-enterprise-scaling/
[7] ZBrain, "Why Enterprise AI Pilots Fail to Scale and How to Address It," 2026. https://zbrain.ai/why-most-ai-pilots-fail-to-scale/
[8] Stratify Insights, "Enterprise AI Scaling Research 2026: Pilot to Production Is Broken." https://stratifyinsights.ai/research/enterprise-ai-scaling-2026
[9] Enterprise Architecture Professional Journal, "Why AI Pilots Fail to Scale," May 2026. https://eapj.org/why-ai-pilots-fail-to-scale/
[10] Astrafy, "Scaling AI from Pilot Purgatory: Why Only 33% Reach Production and How to Beat the Odds." https://astrafy.io/the-hub/blog/technical/scaling-ai-from-pilot-purgatory-why-only-33-reach-production-and-how-to-beat-the-odds