The Agentic AI Stack: What's Actually Running the Best AI-Powered Businesses in 2026
I've been building systems that have to survive contact with reality since 1995, when I launched adoption.com before Google existed. Back then, the question was always the same one I hear from business owners today: "What's actually working, and what's just hype?"
That question is harder than ever to answer in AI, because the hype machine is running at full speed. Everyone's selling a revolution. Most of what I see in my consulting work, though, tells a more honest story: the businesses that are winning with AI have figured out a specific combination of tools that work together, and the businesses that are failing are either doing too little or building on sand.
I'm a medical technologist by training and a business operator by decades of hard practice. I've run operations in seven countries: the United States, Ethiopia, Kenya, Haiti, Mexico, China, and England. I've managed orphanages and humanitarian logistics across three continents. What I know is systems: what makes them hold, what makes them break, and what a capable architecture looks like before you put load on it.
So let me give you the actual answer. Here's what the best AI-powered businesses are running in 2026, translated into plain language, layer by layer.

Why "The Stack" Is the Right Mental Model
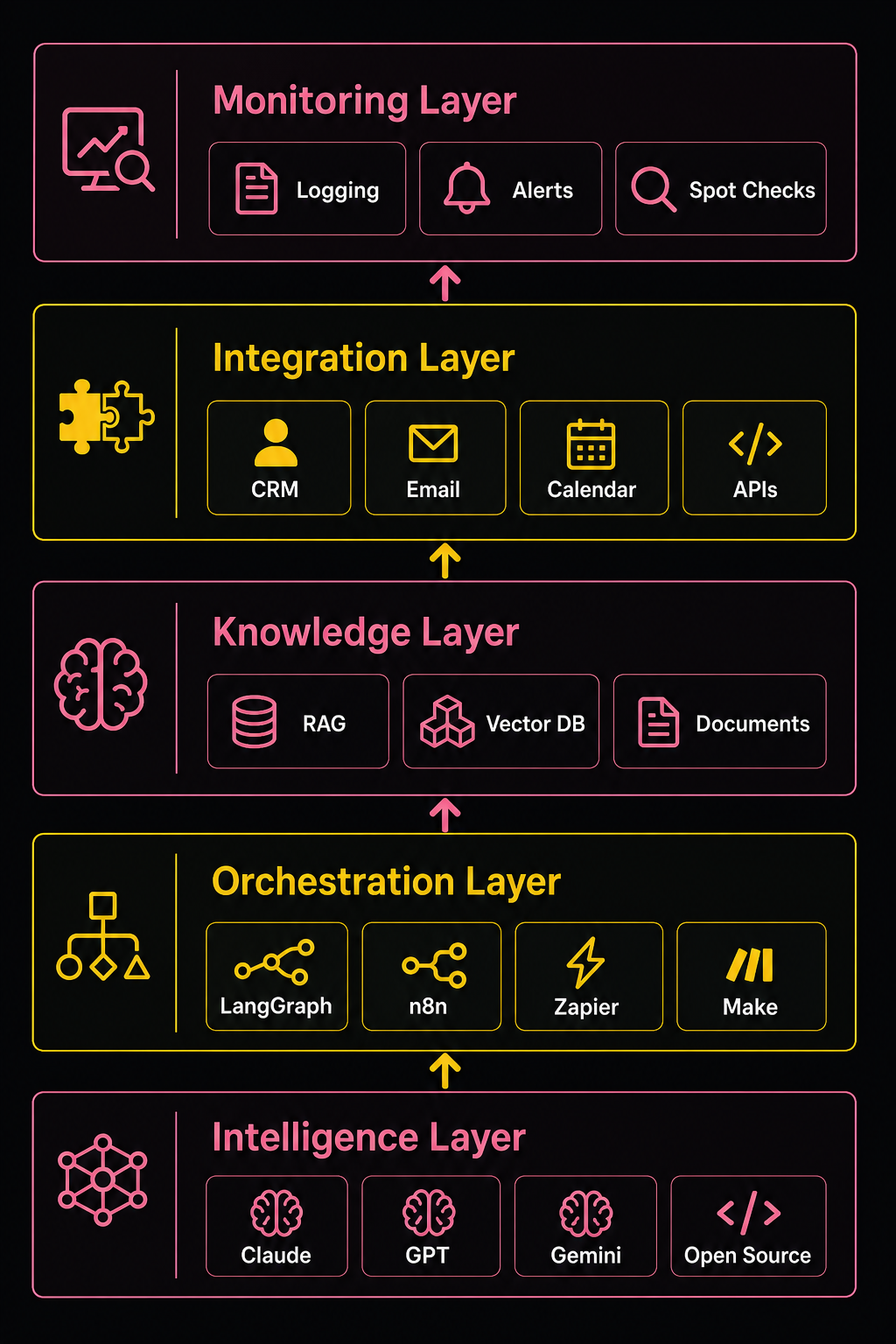
Before I go layer by layer, I want to explain why thinking in stacks matters.
When I was building adoption.com, I had to understand that a website isn't just a website. It's a database layer, a server layer, an application layer, a content layer, and a user layer, all of which have to speak to each other correctly or the whole thing falls apart. A failure in any one layer doesn't just break that layer: it breaks the experience.
AI systems in 2026 work the same way. An LLM on its own is just a very smart text predictor. It doesn't remember your customers. It doesn't know what happened in your last quarterly report. It can't send an email or update a CRM record. The stack is what transforms a raw model into an actual business system.
The AI agents market was valued at $11.55 billion in 2026 and is projected to reach $236 billion by 2034.[1] That kind of growth only happens when the infrastructure matures enough to support real production use. And it has matured. The stack I'm about to describe didn't exist in this form even two years ago.
Layer 1: The Intelligence Layer (Which LLM and Why)
This is the part everyone obsesses over, and it's genuinely important, but it's also the most overcomplicated part of most conversations about AI.
Here's the honest truth: as of mid-2026, the top four frontier models have converged significantly in raw performance. On MMLU-Pro (a graduate-level reasoning benchmark), Gemini 3.1 Pro leads at 90.99%, with Claude Opus 4.7 close behind at 89.87%, a gap of barely one percentage point.[2] On the Artificial Analysis Intelligence Index, Anthropic, Google, and OpenAI are all currently tied at first place, each scoring 57.[2]
So what does differentiate them, in practice?
Claude Opus 4.7: The Precision Choice
I use Claude for the work I care most about. Here's why: on SWE-bench Verified (a software engineering benchmark that tests real code production), Claude Opus 4.7 leads at 87.6%.[2] More importantly for business applications, Claude's hallucination rates on compliance-sensitive extraction tasks remain measurably lower than competitors.[2]
When I'm dealing with contracts, medical data, legal language, or anything where a made-up answer causes real damage, Claude is the model I trust. It's also the strongest choice for multi-file coding tasks, which matters if you're building any kind of custom automation.
GPT-5.5: The Ecosystem Play
If your business is already deeply embedded in Microsoft tools, GPT-5.5 is your default. It integrates tightly with Azure, Microsoft 365, and the broader OpenAI ecosystem. It's also the stronger choice when you need multimodal input: reading a screenshot of a UI, processing an invoice image, analyzing a diagram. GPT-5.5 is the runner-up on coding benchmarks but a strong lead when the workflow involves images or tight Microsoft integration.[2]
Gemini 3.1 Pro: The Context Window Argument
Gemini's biggest differentiator right now is its 10 million token context window, which is 10 times larger than any competitor.[2] That's not a vanity metric. When your AI needs to reason across an entire legal document, your company's full policy handbook, or months of email threads, context window size is the binding constraint. If you're building knowledge-intensive applications, Gemini is worth serious consideration.
Open-Source Options: When to Use Them
I'll be honest: I didn't take open-source LLMs seriously for production business use until 2025. I was wrong. Meta's Llama 4 family and Mistral's models have become genuinely competitive for specific applications, and they offer something the proprietary models can't: you own them.[3]
Llama 4 Maverick handles multimodal reasoning and coding well. DeepSeek V3 delivers benchmark performance competitive with GPT-4.5 on coding tasks at dramatically lower inference cost.[2] If your use case involves processing sensitive customer data that you're not comfortable sending to a third-party API, or if you're processing at a volume where API costs are becoming significant, a self-hosted open-source model deserves evaluation.
The Model Selection Rule I Follow
McKinsey reports that 65% of global organizations are now using generative AI.[4] The ones that succeed pick the right model for the right task. The correct question isn't "which model scores highest on the benchmark leaderboard" but "which model's specific strengths align with the tasks and constraints that determine success in my use case."[2]
Run your actual business tasks against the models you're evaluating. Don't rely on general benchmarks. The results will surprise you.
Layer 2: The Orchestration Layer (How the Pieces Move)
If the intelligence layer is the brain, the orchestration layer is the nervous system. It controls how information flows: when the AI calls a tool, how the output of one step becomes the input to the next, how multiple AI agents coordinate with each other, and how the system recovers when something goes wrong.
This is the layer most business owners don't think about until they try to build something real, and then they realize it's the hardest part.
What Orchestration Actually Does
Without an orchestration layer, you'd have to manually write code for every decision point in your AI workflow: "if the LLM returns X, call the CRM API, then format the response, then trigger the email." Orchestration frameworks handle that plumbing for you. They manage multi-agent coordination, prompt routing, tool integration, memory, and retrieval from external knowledge sources.[5]
There are two categories to understand: code-first frameworks for technical teams, and no-code/low-code platforms for everyone else.
LangGraph: The Technical Standard
LangGraph v1.0 launched in October 2025 and has become the graph-based orchestration leader for production-grade systems.[6] It's used in production at Uber, JPMorgan, LinkedIn, and Klarna.[6] If you have a technical team, LangGraph is what they should be using. It gives you explicit control over the workflow graph: every state, every branch, every tool call is visible and testable. That explicitness is what makes it trustworthy at scale.
Fair warning: LangGraph has a learning curve. Teams that tried LangChain in 2024 and found it too complex now either work with LangGraph (which is more opinionated and controllable) or write thin custom wrappers over provider APIs. Both are legitimate paths.[6]
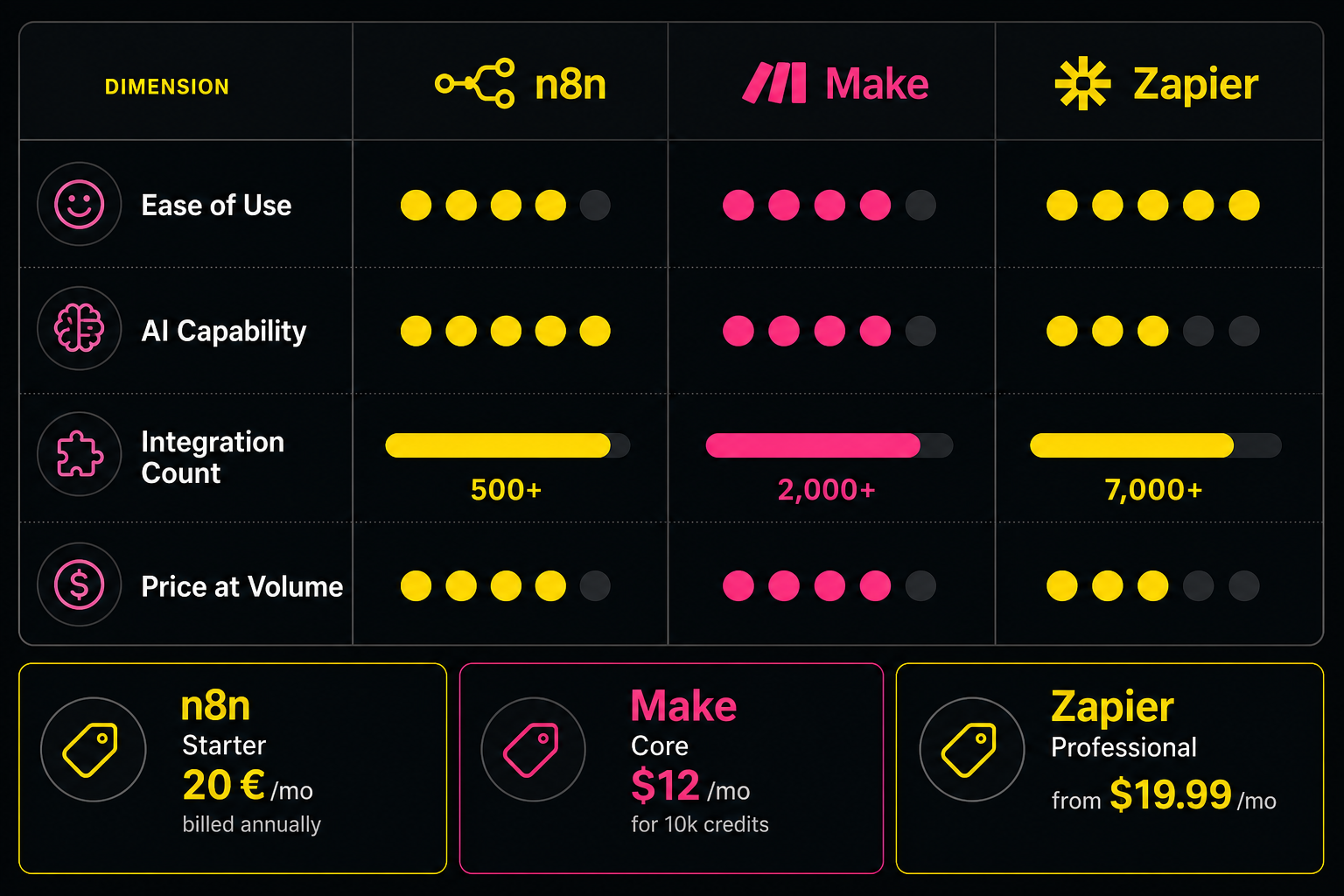
The No-Code Three: Zapier, Make, and n8n
For business operators who aren't developers, or for teams that want to move faster without writing code, there are three platforms that dominate the conversation: Zapier, Make (formerly Integromat), and n8n. They overlap, but they serve different needs.
Zapier is the choice for simplicity and time-to-value. It has over 9,000 integrations, processes more than 10 billion tasks monthly across all its users, and you can build a working automation in under ten minutes with no technical background.[7] Its "Zapier Agents" feature lets you create autonomous AI systems that execute tasks across integrated apps without human intervention. The tradeoff: it gets expensive fast. Paid plans start at $19.99/month for 750 tasks, and a simple workflow processing 100 records already consumes 100 tasks.[7]
Make sits in the middle. It uses a visual canvas interface that makes complex workflows easier to build and debug than Zapier's linear trigger-action model. Paid plans start at $9/month for 10,000 operations, which gives you a much better cost-to-functionality ratio for medium-complexity work.[7] Make has roughly 1,500 native integrations, which covers most mainstream business tools even if it can't match Zapier's breadth.
n8n is the choice for teams that need AI-native depth, data privacy, or high volume at low cost. n8n released a major 2.0 update in January 2026 with native LangChain integration and nearly 70 nodes dedicated specifically to AI applications: LLM chatbots with advanced context management, RAG systems connected to custom data sources, and fully autonomous agents that interact with other services.[7] Self-hosted, n8n costs essentially a flat server fee regardless of how many workflows you run. If you're processing large volumes, this is the economics winner by a significant margin.[7]
The summary I give clients: if you want to start today with no developer, use Zapier. If you want the best price-to-power ratio for visual building, use Make. If AI workflows are central to your strategy and you have at least one technical person, use n8n.
Layer 3: The Knowledge Layer (What the AI Actually Knows)
Here's a problem every business runs into quickly: the AI doesn't know anything about your business.
It knows everything about the general world, but it doesn't know your product catalog, your customer history, your internal policies, your pricing, your processes, or the context that makes your business yours. Without solving this, you have a very smart assistant who doesn't know anything specific about the company they're working for.
The knowledge layer is how you fix that.
What RAG Is, In Plain Language
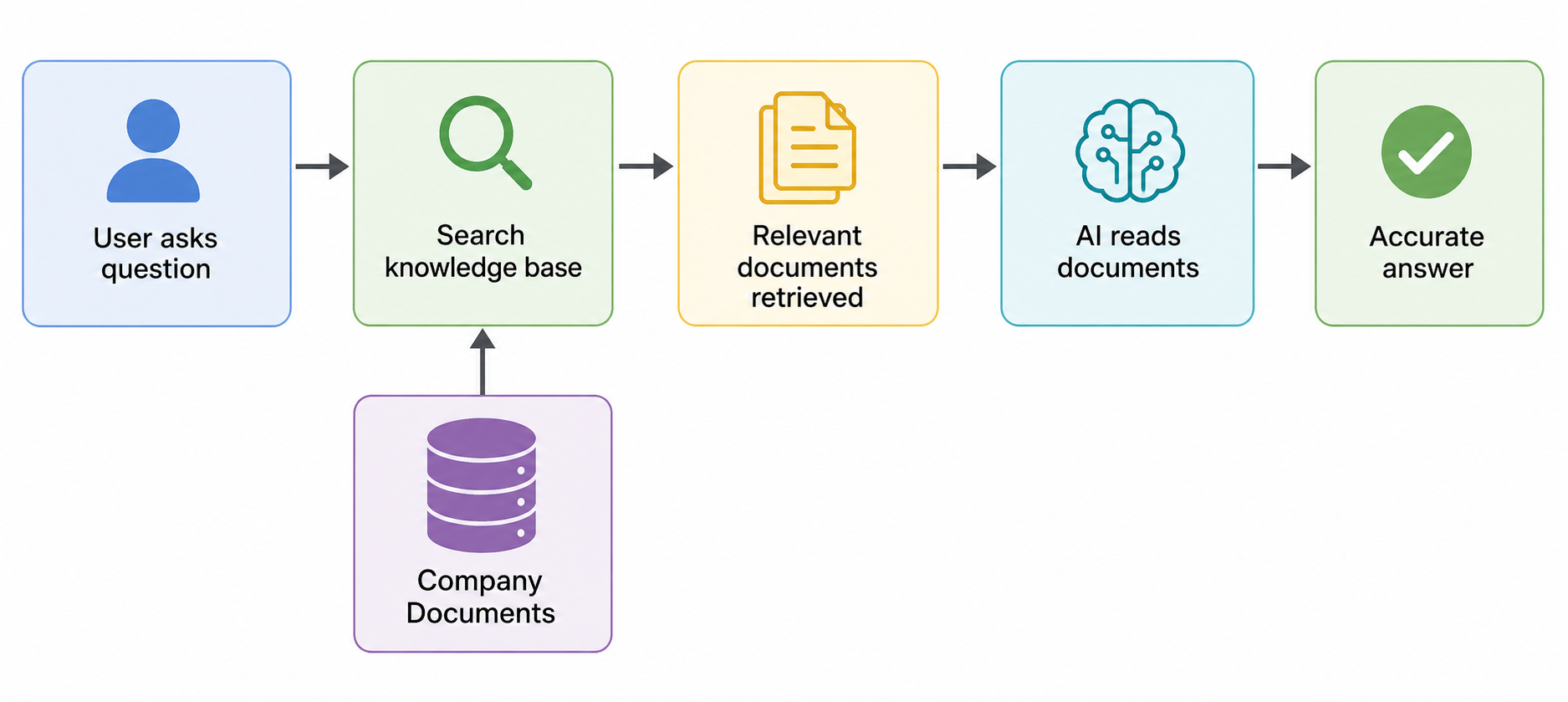
RAG stands for Retrieval-Augmented Generation. It sounds technical. The concept is actually simple.
Imagine you have 10,000 pages of company documentation. You can't stuff all of that into an AI prompt: it would be too long, too expensive, and the AI would get confused. Instead, RAG does this: when someone asks a question, the system first searches your documentation for the most relevant passages, then gives those specific passages to the AI as context, then asks the AI to answer based on what it just read.
The result is an AI that can accurately answer questions about your specific business, using your actual documents, with far fewer made-up answers than a model operating from memory alone. It's the difference between asking a consultant who read a one-page summary of your company and asking one who just spent three hours in your files.
Vector Databases: The Engine Behind RAG
The technology that makes RAG fast is a vector database. When you load your documents into a RAG system, each piece of text is converted into a mathematical representation (called an embedding) that captures its meaning. Vector databases like Pinecone and Weaviate store these embeddings and can search them at speed.[5]
When a query comes in, it's converted to the same kind of mathematical representation, and the database finds the documents with the closest meaning, not just keyword matches. That's why a question about "refund policy" can retrieve a document that uses the words "return window" and "money-back guarantee" without those exact keywords appearing in the question.
For small businesses just getting started: you don't need to build this from scratch. n8n has RAG built into its node library. Many AI platforms offer it as a feature. The important thing is to understand that it exists and that it's how you give the AI genuine knowledge of your business.
What Goes in the Knowledge Layer
Practically speaking, the most valuable things to load into your knowledge layer are:
- Internal documentation and process guides
- Product and service information
- Historical customer communications (anonymized where necessary)
- Sales scripts and objection handling notes
- Compliance requirements and policy documents
The quality of what goes in determines the quality of what comes out. Garbage in, garbage out still applies even with the best AI on the front end.
Layer 4: The Integration Layer (How AI Connects to Everything Else)
An AI that can reason but can't act is just an expensive search engine. The integration layer is what gives AI the ability to do things: send an email, create a CRM record, pull data from your accounting software, update a spreadsheet, post to a website, or trigger a workflow in another system.
APIs, Webhooks, and Connectors
The building blocks of the integration layer are APIs (application programming interfaces) and webhooks. An API is a formal connection point that lets one system request data or actions from another. A webhook is a notification that fires automatically when something happens: "a new form was submitted," "a payment was processed," "a customer opened an email."
The good news is that most of the plumbing here gets handled by the orchestration platforms I described in Layer 2. Zapier's 9,000+ integrations, Make's 1,500 connectors, and n8n's growing library of nodes abstract away the raw API work for most common business tools.
The Protocol That Standardized Everything: MCP
One development that significantly changed the integration landscape in 2025 was the release of MCP (Model Context Protocol), originally created by Anthropic in November 2024 and donated to the Linux Foundation's Agentic AI Foundation in December 2025.[8] MCP is now the standard way LLMs connect to external tools and data sources, with Claude alone supporting 75+ MCP connectors.[8]
What MCP solved was the integration tax. Before MCP, every AI tool needed its own custom integration with every other tool. MCP creates a standard "plugin socket" that any AI model can use to connect to any tool that supports the protocol. Google's competing Agent-to-Agent (A2A) protocol, which solves how AI agents communicate with each other, now has 150+ supporting organizations.[8]
I'm not describing this because you need to know the technical details. I'm describing it because it explains why AI integrations in 2026 are meaningfully easier to build than they were even 18 months ago.
What to Prioritize in Your Integration Layer
From working with businesses across multiple industries, the highest-value integrations to build first are almost always:
- Your CRM (where customer data lives)
- Your email platform (where most customer communication happens)
- Your calendar or scheduling system
- Your project management or ticketing tool
- Whatever system you use for financial data
These five integrations, connected to an AI orchestration layer with a solid knowledge base behind it, can automate a substantial portion of the administrative work that currently consumes your team's time.
Layer 5: The Monitoring Layer (How You Know It's Working)
I saved this for last because it's the layer most people skip, and it's the layer that kills AI projects.
Here's a statistic that should give every business owner pause: 42% of AI projects show zero ROI.[9] The most common reason isn't bad AI. It's that teams deploy AI, declare victory, stop watching, and have no idea when it starts producing wrong answers, looping, failing silently, or degrading over time.
Coming from a medical technology background, I find this alarming. In clinical laboratory medicine, you don't just run an analyzer and trust it. You run quality controls. You track drift. You have alarms for out-of-range values. You have people whose job is to catch when the machine is lying to you. AI systems need the same discipline.
What Can Go Wrong Without Monitoring
An AI agent in production might:
- Start hallucinating answers when its knowledge base goes stale
- Get stuck in a loop calling the same tool repeatedly
- Fail silently when a connected API returns an error, producing no output rather than flagging the problem
- Drift in behavior when the underlying model gets updated by its provider
- Generate outputs that were correct during testing but fail on edge cases in real data
Any of these would go undetected without monitoring, and several of them could cause real business harm: wrong information sent to customers, missed tasks, corrupted data.
The Monitoring Tools That Are Working in 2026
IBM research found that companies with mature orchestration-led governance were 13 times more likely to scale their agentic AI stacks successfully.[10] The tools making that governance possible include LangSmith (for tracing every decision point in a LangGraph workflow), Arize (for drift detection and model performance over time), and Helicone (for logging, cost tracking, and quality monitoring across LLM calls).[10]
Even if you're not running a complex technical setup, there are three things I consider non-negotiable for any AI deployment:
Logging: Every interaction the AI has with customers or internal systems should be logged somewhere you can review. Not because you'll read every one, but because when something goes wrong, you need the receipts.
Sampling and spot checks: Somebody on your team should be reading a random sample of AI outputs regularly, not just when there's a complaint. Errors in AI outputs often appear first as a slow drift that nobody notices until it's a pattern.
Alerting on failure states: Your AI workflows should be set up to alert someone (by Slack, email, or whatever you actually check) when they error out, when they fail to complete, or when response times become abnormal. Silent failures are the worst kind.
The Full Picture: What a Real Agentic Stack Looks Like
Let me make this concrete. Here's the stack a typical service business running a serious AI operation might have in mid-2026:
Intelligence layer: Claude Opus 4.7 for compliance-sensitive work and complex reasoning, GPT-5.5 for tasks requiring image understanding, Mistral Medium 3.5 self-hosted for high-volume classification tasks where cost matters.
Orchestration layer: n8n for AI-native workflow automation, with LangGraph for the more complex multi-agent workflows that require state management and branching logic.
Knowledge layer: A Pinecone or Weaviate vector database loaded with company documentation, product information, and historical customer data, powering RAG for any customer-facing AI interactions.
Integration layer: n8n connecting CRM, email platform, calendar, invoicing system, and relevant data sources, using MCP-compatible connectors where available.
Monitoring layer: LangSmith for tracing, Helicone for cost and quality logging, weekly human spot-checks of AI output samples, and Slack alerts on workflow errors.
This isn't the cheapest setup, and it isn't the simplest. But it's what I see working. The businesses with stacks that look roughly like this are among the 58% with positive ROI. The ones without a monitoring layer, or without a knowledge layer, or who chose an orchestration tool based on what was popular rather than what fit their technical capability, are frequently in the 42% with nothing to show for it.
My Direct Recommendation
I've been building systems for 30 years. What I know is that the question isn't whether to build an agentic AI stack. The market is moving fast enough that not building one is itself a strategic decision with consequences. The AI agents market is on track to go from $11.55 billion in 2026 to $236 billion by 2034.[1] The businesses being built on solid AI stacks right now have structural advantages that will compound for years.
The question is where to start. And my answer is always the same: start at the integration layer, not the intelligence layer.
Most businesses I talk to want to start by picking an LLM, because the models feel like the exciting part. But the models are the least differentiated part of the stack right now. The top frontier models are nearly tied on raw performance. Where businesses actually diverge is in what their AI can access, what it knows, and whether they can tell when it's failing.
Start by mapping what your AI needs to connect to. Then build the knowledge layer that gives it context about your business. Then choose the orchestration platform that matches your team's technical capability. Then add monitoring before you put it anywhere customer-facing. The intelligence layer almost picks itself once you know what the system needs to do.
That's the sequence I follow at Verity Agentic, and it's the same sequence I've followed building systems in resource-constrained, high-stakes environments for three decades. I learned it partly from my Cap Gemini background (where you don't build before you understand the integration surface) and partly from running humanitarian operations in places where a broken system wasn't an inconvenience, it was a gap in service delivery for people who had no alternative.
I'm building my AI consulting track record right now, same as you might be building your AI strategy. What I bring to that work isn't a long client list. It's 30 years of knowing the difference between architecture that holds and architecture that just looks good in a presentation.
The technology is genuinely capable. The stack is more mature than it was even 18 months ago. What's holding most businesses back isn't the AI. It's the architecture around it.
Build that architecture right, and the AI does its job.
Sources
[1] Precedence Research, "AI Agents Market Size, Share & Trends Analysis Report," https://www.precedenceresearch.com/ai-agents-market, 2026
[2] ideas2it, "Top 8 LLM Comparisons for Enterprise in 2026: GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, Grok 4 & Llama 4," https://www.ideas2it.com/blogs/llm-comparison, 2026
[3] Azumo, "Best LLMs Right Now: June 2026 Model Rankings & Use Cases," https://azumo.com/artificial-intelligence/ai-insights/top-10-llms-0625, 2026
[4] McKinsey & Company, via Incremys, "LLM 2026 Statistics: Performance Analysis and Benchmarks," https://www.incremys.com/en/resources/blog/llm-statistics, 2026
[5] AIMultiple, "The 7 Layers of Agentic AI Stack," https://aimultiple.com/agentic-ai-stack, 2026
[6] O'Reilly, "The AI Agents Stack (2026 Edition)," https://www.oreilly.com/radar/the-ai-agents-stack-2026-edition/, 2026
[7] Digidop, "n8n vs Make vs Zapier: Which Automation Tool Should You Choose?," https://www.digidop.com/blog/n8n-vs-make-vs-zapier, 2026
[8] O'Reilly, "The AI Agents Stack (2026 Edition) , MCP and A2A protocols," https://www.oreilly.com/radar/the-ai-agents-stack-2026-edition/, 2026
[9] Beam.ai, "Why 42% of AI Projects Show Zero ROI (And How to Be in the 58%)," https://beam.ai/agentic-insights/why-42-percent-of-ai-projects-show-zero-roi-and-how-to-be-in-the-58-percent, 2026
[10] CoreSignal, "Agentic AI Tech Stack 2026," citing IBM research, https://coresignal.com/blog/agentic-tech-stack/, 2026